본 포스트에서는 머신러닝기반 이상감지 모델개발 시 고려해야할 데이터의 특징에 대해 간략하게 설명하도록 하겠습니다.
작성자 : 박상민 - (주)인스페이스 미래기술실 연구원
본 포스트는 약 4개월간 이상감지(Anomaly Detection)를 연구하게 되면서 공부했던 것, 알아낸 것, 찾아봤던 자료, 구현체, 결과물 등을 정리해서 공유하는 글 입니다.
주관적인 내용이 포함되어 있으니 이해해주시기 바랍니다. 항공우주분야의 이상감지를 연구해왔기 때문에 글의 내용도 도메인에 밀접한 내용이 있으니 참고하시면 좋을 것 같습니다.
이상감지와 데이터
데이터의 시간적 특성
이상감지분야에 딥러닝을 적용하다보면 가장 큰 문제는 데이터 입니다. 특히 시계열 데이터에서 ‘시간’적인 특성을 잘 고려해야 합니다.
기존의 OOL기법, 클러스터링 등은 시간적인 특성을 고려하지 않은 기법들입니다. 하지만 현실에서는 시계열 데이터가 대부분이고, 시간적인 특성을 가지고 있습니다. 위성에서 원격으로 보내주는 Telemetry 데이터 또한 시계열 데이터이고, 시간적인 패턴이 있습니다.
시간적인 특성을 고려하지 않고, 모델을 개발한다면 시간이 지남에따라 조금씩 누적되어지는 이상징후 등을 감지할 수 없습니다.
데이터 정의(Normal / Novelty / Anomaly)
정상과 이상을 정의하는 것도 중요합니다. 무엇이 정상이고, 무엇이 이상인지 도메인 전문가는 알고 있어야 합니다. 여기서 novelty와 anomaly의 차이를 알고가시면 좋을 듯 합니다.
Novelty의 뜻은 새로운이라는 뜻 입니다. novelty detection은 anomaly(이상)를 찾는것이 아니라, 정상과는 다른 새로운 패턴 또는 형태의 데이터를 찾는 것 입니다. 새로운 패턴, 형태의 데이터에는 어쩌면 anomaly(이상)가 있을수도 있습니다.
하지만 무조건 이상 데이터라고는 할 수는 없겠죠. 이상이라고는 할 수 없지만, 정상데이터와는 다른 새로운 데이터라고 생각하시면 될 것 같습니다. 범위로보자면 novelty가 anomaly보다 더 큰 범위이겠네요.
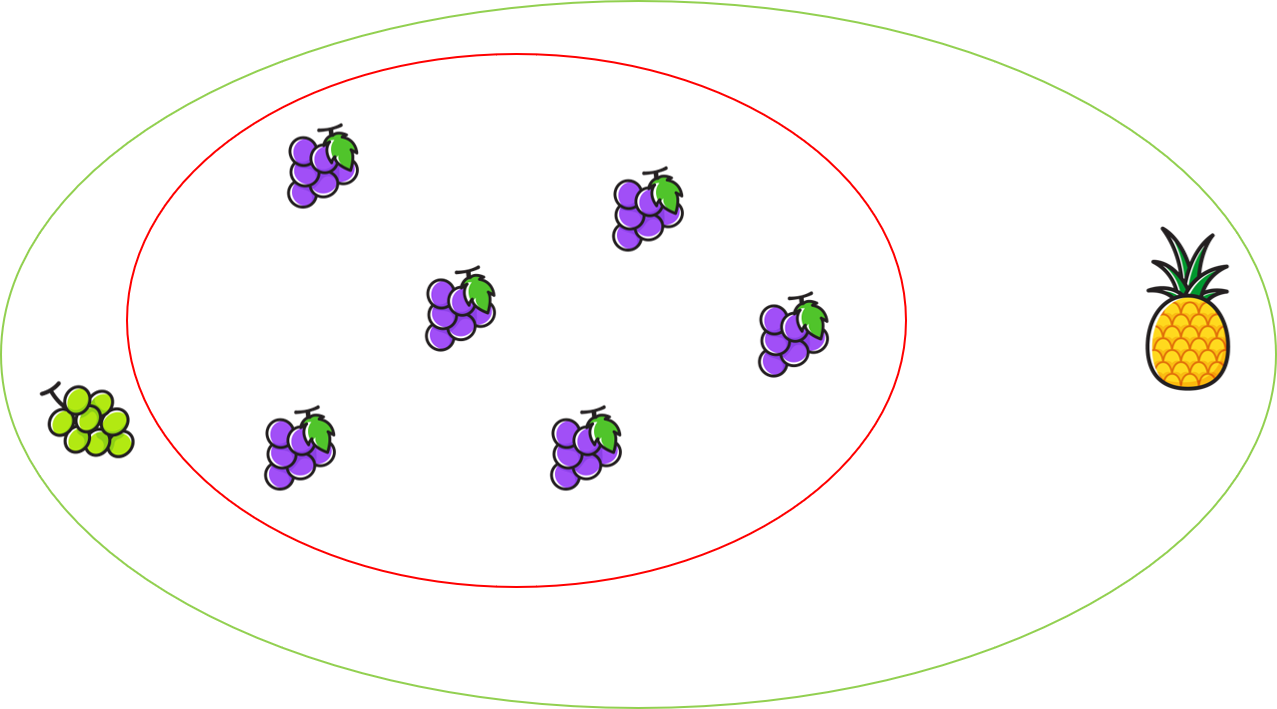
위 사진을 보시면 더 수월하게 이해가 될 것 같습니다. 위와같이 과일이 있을 때, 보라색포도는 정상입니다. 보라색포도가 정상이라고 했을 때 위 그림에서 anomaly(보라색 포도와는 다른 이상한과일)를 찾고자 합니다.
청포도와 파인애플은 novelty 데이터입니다. 보라색 포도(정상데이터)와는 다르니깐요. 여기에서 청포도를 바라보는 사람에 따라 입장차가 있을 수 있습니다. 과일을 잘 모르는 사람이 봤을 때, 청포도가 anomaly 라고 생각할 수도 있습니다(색이 다르기 때문에).
하지만 과일을 잘아는(과일상점 주인) 사람이 봤을 때는 청포도는 anomaly라고 단정하기 보다는 새로운 종류(novelty)의 포도라고 생각할 수도 있습니다.(색깔이 다를뿐 그 외에는 똑같기 때문에)
Novelty를 청포도라하고, anomaly를 파인애플이라고 정의했다면, novelty deection은 청포도와 파인애플을 모두 찾는데 집중을 해야합니다. anomaly detection이라고 한다면, 파인애플을 찾는데 집중을해야겠죠.
위와같은 상황은 언제든지 발생할 수 있습니다. 그러므로, 도메인 전문가의 명확한 데이터 정의가 매우 중요합니다. 데이터 정의에 따라 모델의 목표와 성능, 개발 방향이 달라지기 때문입니다. 관습적으로는 novelty/anomaly detection을 혼용해서 같은 의미로 사용합니다.
비정상데이터의 이해
비정상데이터의 이해도 필요합니다. 출처
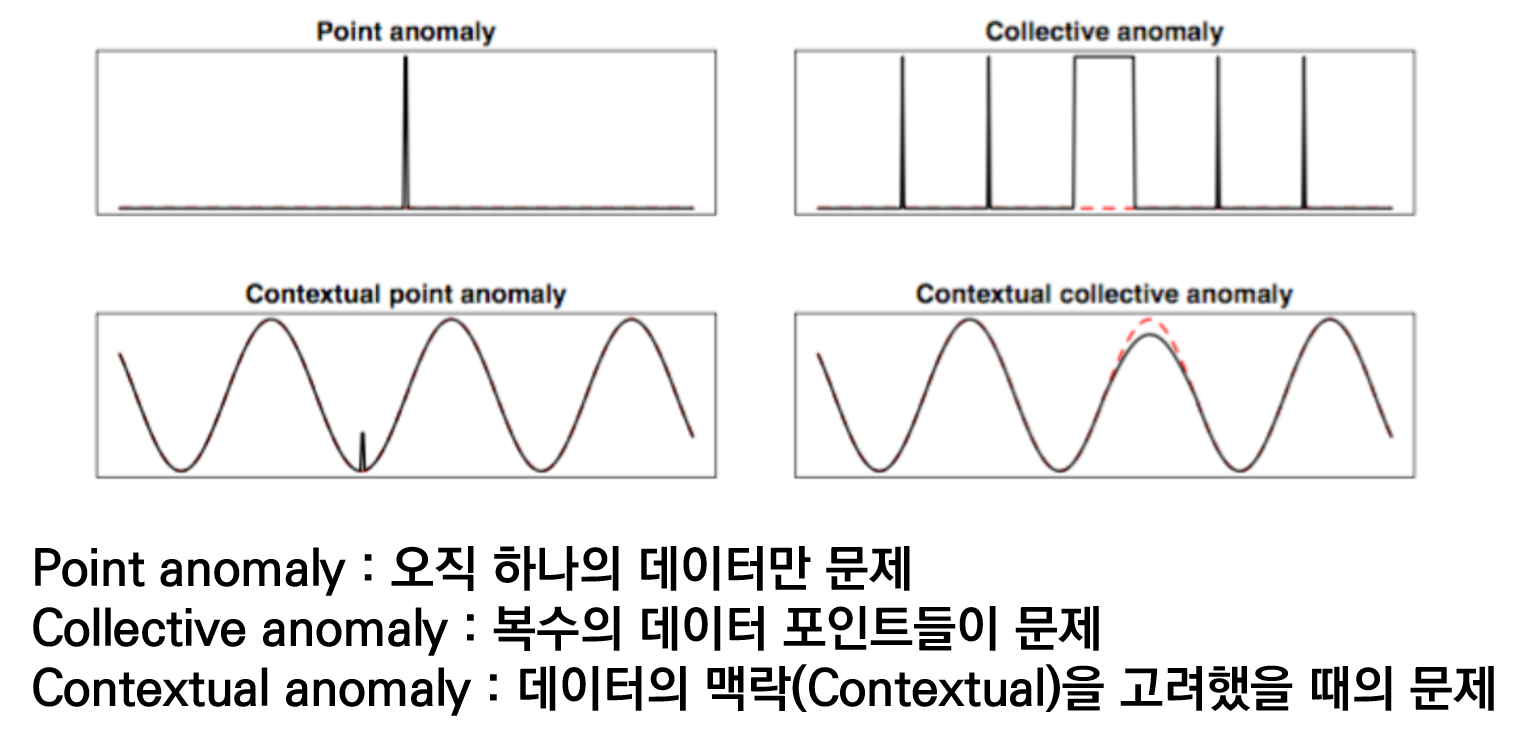
Point anomaly : 오직 하나의 데이터에만 이상이 생긴 것 입니다. 데이터들의 그룹에서 떨어져있는 값 입니다. Point anomaly는 수월하게 찾을 수 있습니다. OOL, 클러스터링 등을 이용해서도 쉽게 찾을 수 있습니다.
Collective anomaly : 복수의 데이터 포인터들에게서 이상이 생긴 것 입니다.
Contextual anomaly : 데이터의 맥락(Contextual)을 고려했을 때 생긴 이상이 생긴 것 입니다. 대부분의 시계열 데이터에는 contextual한 부분을 고려해야 합니다. 패턴이 있고, 정상적인 패턴중에서 비정상적인 패턴이 나오는 경우가 많습니다.
4번째 contextual collective anomaly와 같은 이상데이터는 탐지하기가 굉장히 어렵습니다. 시계열 데이터의 이상감지를 연구하는 사람들의 최종목표는 contextual collective anomaly를 탐지하는 시스템을 개발하는 것이 아닐까 생각합니다.
데이터 그룹화
대부분의 데이터는 다변수 시계열 데이터입니다. 다변수 시계열 데이터일 경우, 각 변수들을 유사한 변수들끼리 묶어 그룹을 만드는게 중요합니다. 예를 하나 들어보겠습니다.
우주선의 이상을 감지하는 시스템을 구축하고자 합니다. 100개의 변수가 있을 때 100개의 변수를 모두 하나의 그룹으로 생각해서 이상감지 시스템을 구축하는게, 우주선의 전반적인 상태를 모니터링 할 수 있다고 생각하여 하나의 그룹으로 시스템을 구축하였습니다.
시스템에서 이상이 생겼을 경우, 경고 알람을 보내줄 것입니다. 모니터링 담당자는 알람을 보고 대응을 하겠죠. 하지만, 현실적으로 대응을 하고자 할 때 세부적인 대응을 할 수가 없습니다. 우주선의 굉장히 많은 시스템 중에(1단 로켓, 2단 로켓, 엔진, 연료통, 궤도, 고도, 온도 등) 어떤 부분에서 이상이 생겼는지 알 수가 없기 때문입니다.
이제 담당자는 각각의 센서 그룹(1단로켓, 2단로켓, 엔진 등)에 해당하는 실제 데이터들을 살펴볼 것입니다. 엔진관련 변수들을 살펴보고, 1단 로켓 관련 변수들을 살펴 볼 것입니다. 총 10개의 그룹이 있다면 하나씩 다 살펴봐야겠죠?
위 사례가 수백개의 변수가 있을 때 각 유사한 그룹으로 나누지않고, 하나의 전체적인 그룹으로 생각하고 시스템을 구축했을 때 생길 수 있는 문제점이라고 생각합니다. 또 다른 예를 하나 들어보겠습니다.
우주선의 이상을 감지하는 시스템을 구축하고자 합니다. 100개의 변수가 있을 때 100개의 변수중에서 유사한 변수끼리(1단 로켓 변수는 1단로켓 변수 그룹으로 묶고, 엔진 변수들은 엔진 변수 그룹으로 묶는 등)그룹을 묶어 총 10개의 그룹을 묶었습니다.
각 그룹마다 각각의 이상감지 시스템을 구축하였습니다.(즉, 각 그룹마다 이상감지 모델이 있는 것이고, 총 10개가 될 것입니다.) 이상이 생겨 시스템에서 경고 알림을 보내줍니다. 10개의 시스템 중 엔진 시스템에서 이상이 발생해 경고알림을 보내줍니다.
모니터링 담당자는 엔진에 이상이 감지된 것을 확인하고, 메뉴얼에 따라 대응 할 것입니다.(물론 현실적으로는 좀 더 자세한 분석이 들어가야겠죠?)
2개의 사례를 예로 들었습니다. 실제로 제가 참고한 논문중에서도 각각의 채널(그룹)마다 독립적인 모델을 만들고, 운영하는게 바람직하다고 제안하였습니다. 각 그룹마다, 데이터도 다르기 때문에 모델도 독립적으로 만들고, 학습도 따로 시켜야겠죠.
운영하는 입장에서도 독립적인 시스템이 실제 이상이 생겼을 때 더 세부적으로 대응할 수 있지 않을까 생각합니다. 수백개의 변수 중에서 도메인 전문가는 유사한 각 변수들을 그룹지어서(4~5개 등) 데이터를 구축하는게 맞다고 생각합니다.
한 그룹의 변수가 A ~ E까지 있다고 하였을 때, A 데이터에 이상이 생기면 B, D 데이터에도 영향을 미치는(유사하게 움직이는)변수들이 있습니다. 이러한 도메인적인 특성을 잘 이해하고, 반영해야 합니다.