본 포스트는 NASA에서 Spacecraft Telemetry 데이터에 이상감지 모델을 적용한 논문을 간단하게 정리한 글 입니다.
작성자 : 박상민 - (주)인스페이스 미래기술실 연구원
본 포스트는 약 4개월간 이상감지(Anomaly Detection)를 연구하게 되면서 공부했던 논문, 구현체 등을 정리해 공유하는 글 입니다.
항공우주분야의 이상감지를 연구해왔기 때문에 대부분의 내용이 도메인에 밀접한 내용이 있으니 참고하시면 좋을 것 같습니다.
10. Detecting Spacecraft Anomalies Using Nonparametric Dynamic Thresholding 10
본 논문은 NASA에서 작성하였습니다.
기존 이상징후 감지 기법
- OOL (Out of Limit)
- 사전에 정의된 limit 값을 기준으로 이상치 탐지
- Expert system
- 전문가들의 지식을 이용하여 순서도를 만들어 이상치 탐지
- Distance based
- 특징 추출 후 군집화를 진행하여 거리 기반 이상치 탐지
- Density based
- 특징 추출 후 군집화를 진행하여 밀도 기반 이상치 탐지
- Visualization
- 특징 추출 후에 시각화를 하여 전문가들의 소견으로 이상치 탐지
기존 이상징후 감지 기법의 문제점
-
기존의 spacecraft에서 원격으로 보내준 데이터(telemetry)들의 이상감지 모니터링을 하는 시스템을 유지하는데 굉장히 많은 비용과 전문지식이 필요하다.
-
현재의 이상탐지 방식은 값이 사전 정의 된 한계를 벗어나는 방법, 시각화 및 통계를 통해 수작업으로 분석하는 방법을 사용하는 경우가 많다.
-
OOL기법이 많이 증가하고 있지만, 데이터의 양이 증가하면서 한계점이 드러나고 있다.
-
이런 문제는 Spacecraft에서 보내주는 데이터가 많을수록, 점점 더 악화될 것 이다. (NISAR라는 위성은 하루에 85테라바이트의 데이터를 보냄)
- 전문 인력 필요
- 고도의 전문 지식 필요
- 이상치를 잘 놓치는 경향이 있음
- 축적 데이터 기반으로 하여 메모리 과부하
- 과도한 계산으로 인한 컴퓨팅 파워 부족
논문에서 제안한 해결 방법
-
다변수의 시계열 데이터에서 이상징후를 찾는 것은 엄청난 도전이다.
-
SMAP인공위성과 MSL rover의 라벨링 된 데이터를 이용하여 LSTM을 사용해 문제들을 극복하고자 한다.
-
기존의 방식들은 시계열 데이터에서 시간과 관련된 이상징후를 누락하는 문제점 등이 있어, LSTM과 같은 순환신경망으로 이를 해결하고자 한다.
-
OOL의 한계점을 순환신경망으로 접근한다면 해결할 수 있다.
-
최근들어 획기적으로 신경망(NN)이 sequence to sequence를 포함한 다양한 분야에서 향상되었기에 가능하다고 보고있다.
-
LSTM의 예측성능은 기존의 항공우주산업 프로그램에서 담을 수 없던 시간정보를 담을 수 있기 때문에 매우 중요하다.
-
무엇보다 LSTM은 과거의 데이터를 기억하고, 현재 예측에 영향을 미치는 구조가 효과적이고, 다변수인 상황에서 차원 감소나, 도메인 지식이 없어도 시계열 데이터를 잘 표현할 수 있다는 것이 장점이다.
-
LSTM의 장점들이 모티브가 되서 LSTM네트워크를 이상감지에 적용시켰다.
-
LSTM네트워크를 이용해 정상 telemetry sequences와 command를 예측하는 것을 학습하고, unsupervised thresholding을 사용해 데이터를 자동 평가하고, 이상을 감지한다.
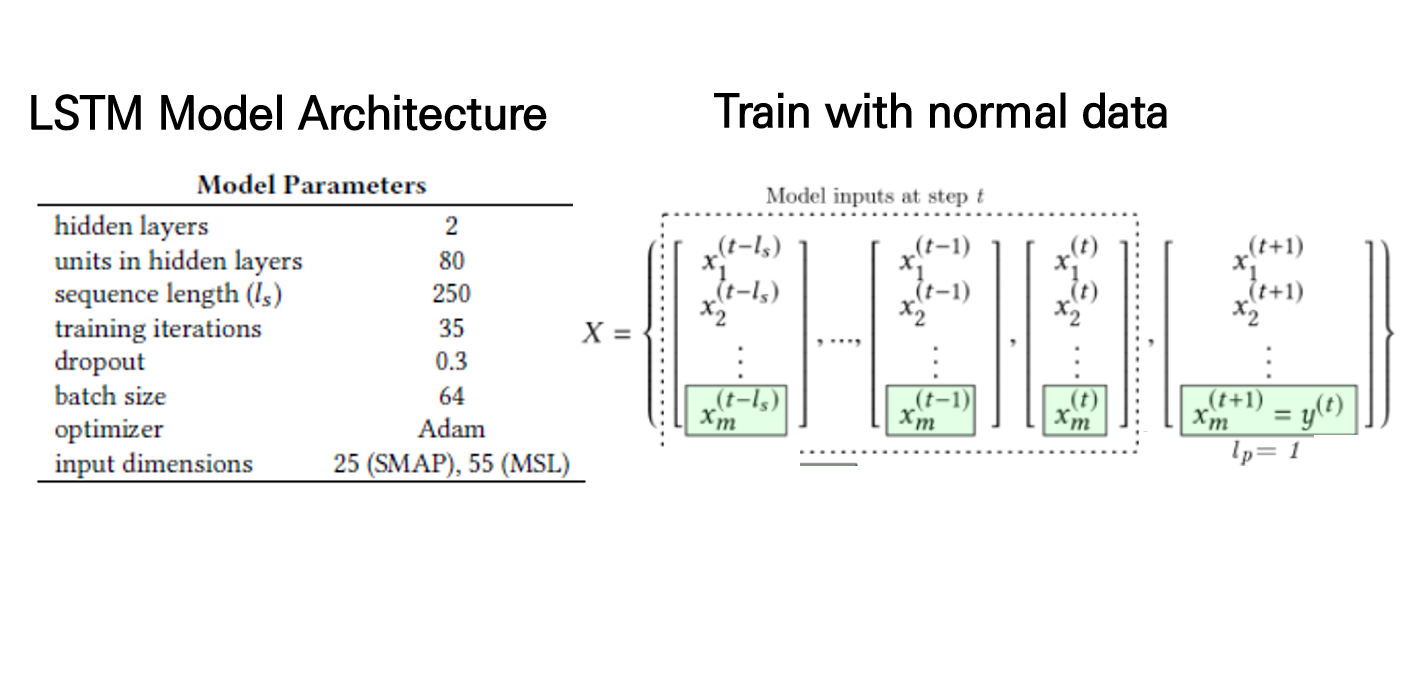
LSTM 모델 구조
LSTM 모델 구조를 보여주는 사진입니다. 모델은 normal(정상)데이터로 학습을 진행합니다.
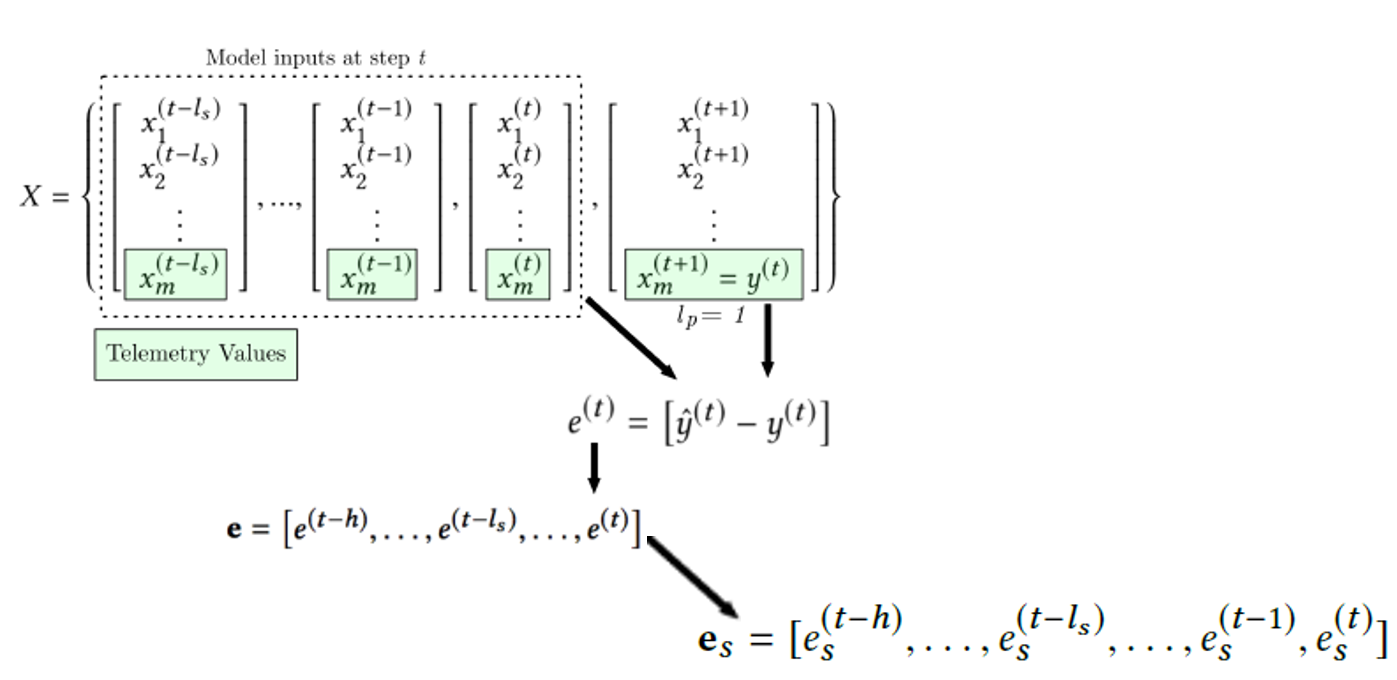
모델 입력/출력/Error Setting
모델의 입력, 출력(예측), error setting의 시퀀스를 보여주는 사진입니다. error를 이용해 threshold를 설정하고, 이상감지를 진행합니다.
Dynamic Error Threshold 기법
Non-Parametrict Thresholding 수식입니다. Error 값에 따라 threshold가 유동적으로 바뀌게 됩니다. Unsupervised thresholding 기법이라고 설명하고 있습니다.
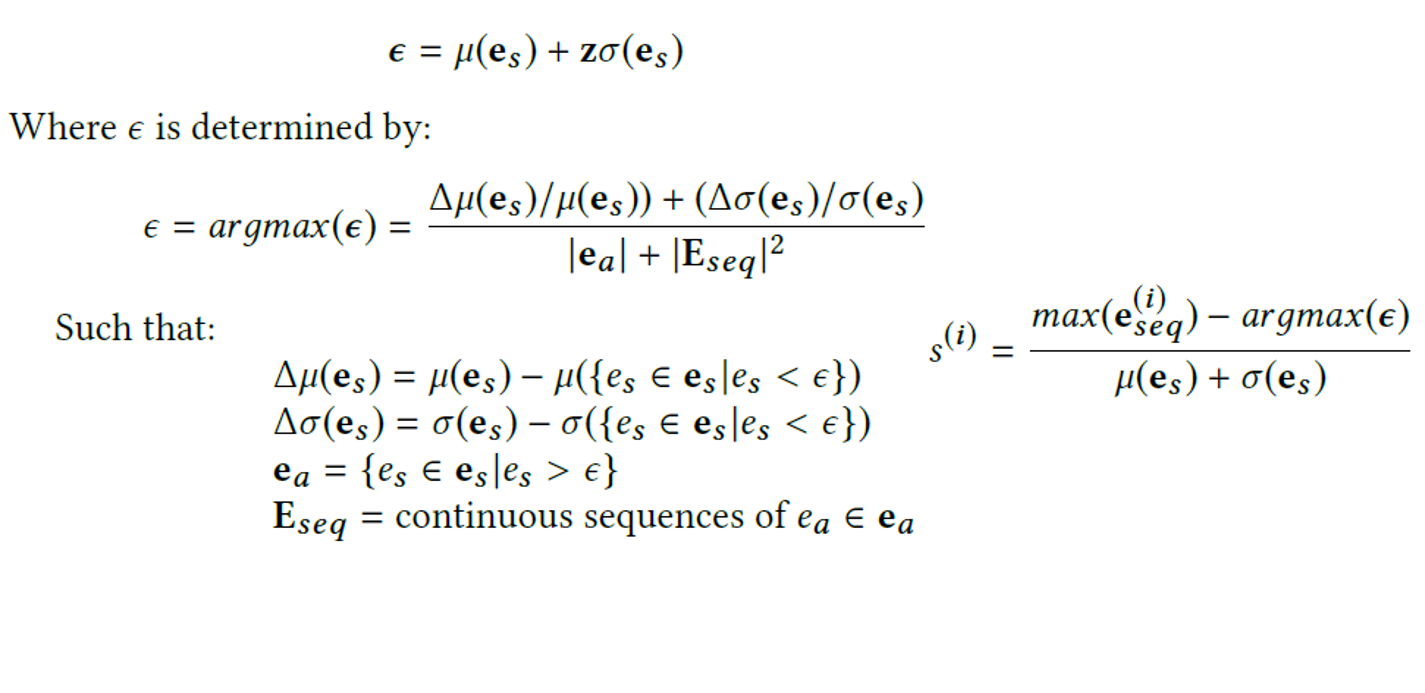
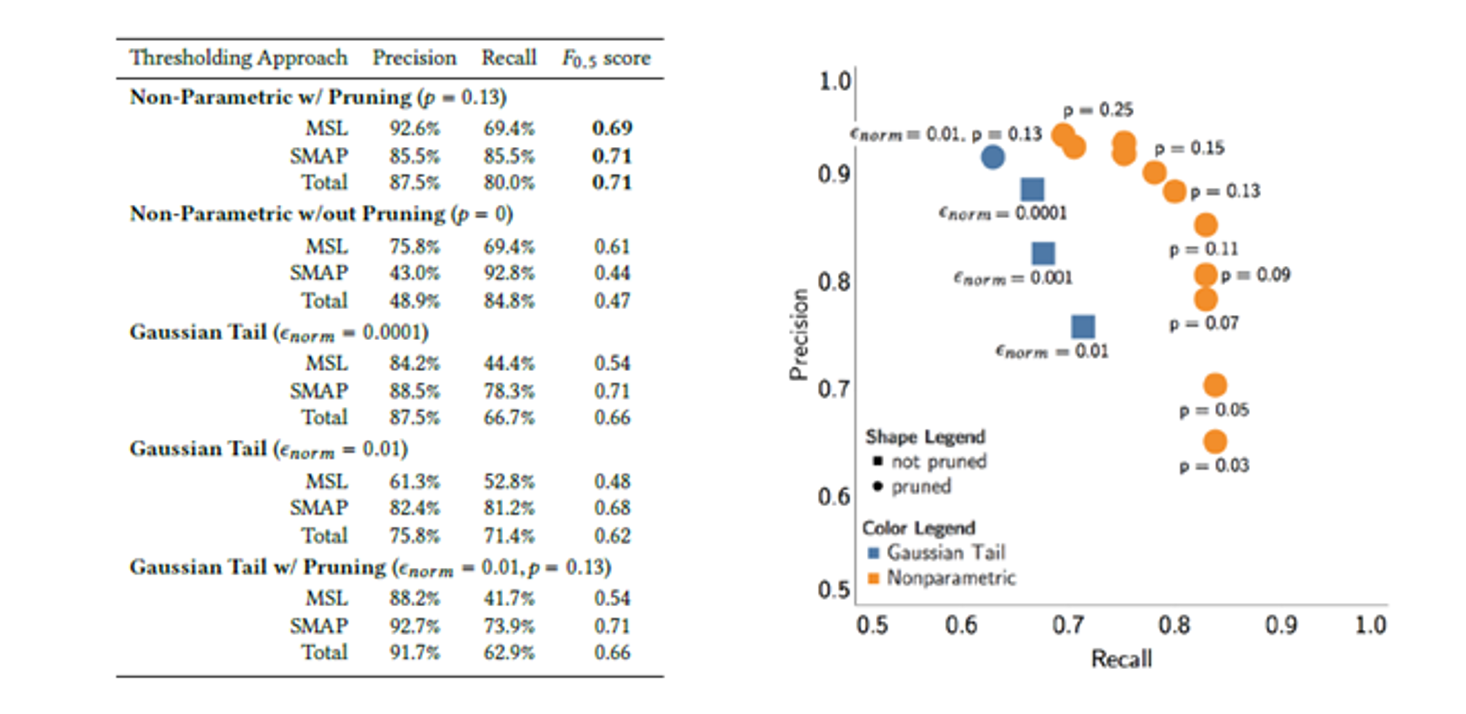
모델 성능 평가 지표
다양한 Threshold 기법을 적용한 모델 성능평가 지표입니다. Non-Parametric 기법과 Pruning(가지치기)기법을 사용하였을 때 가장 좋은 성능이 나왔습니다.
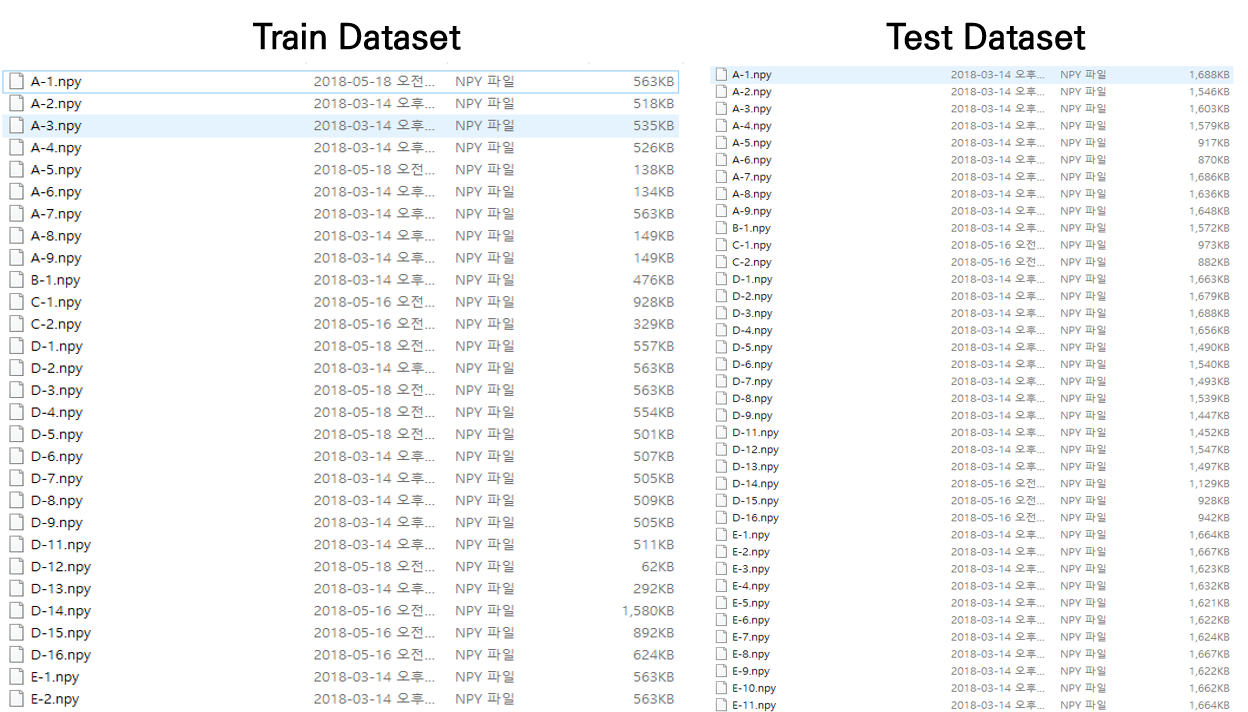
데이터 셋 구축
실제 저자가 사용한 데이터 셋 입니다. Github에 올려져 있습니다. 학습 셋과 테스트 셋이 나뉘어져 있습니다. 학습셋은 정상 데이터, 테스트 셋은 정상 + 비정상데이터(라벨링 된)로 구성되어 있습니다.
테스트 데이터 셋 라벨링
테스트 셋은 라벨링 되어 있습니다(labeled_anomalies.csv 참고). 이상구간 인덱스와, 이상의 종류, 데이터 셋 이름 등의 대한 정보가 csv파일형태로 구성되어 있습니다.
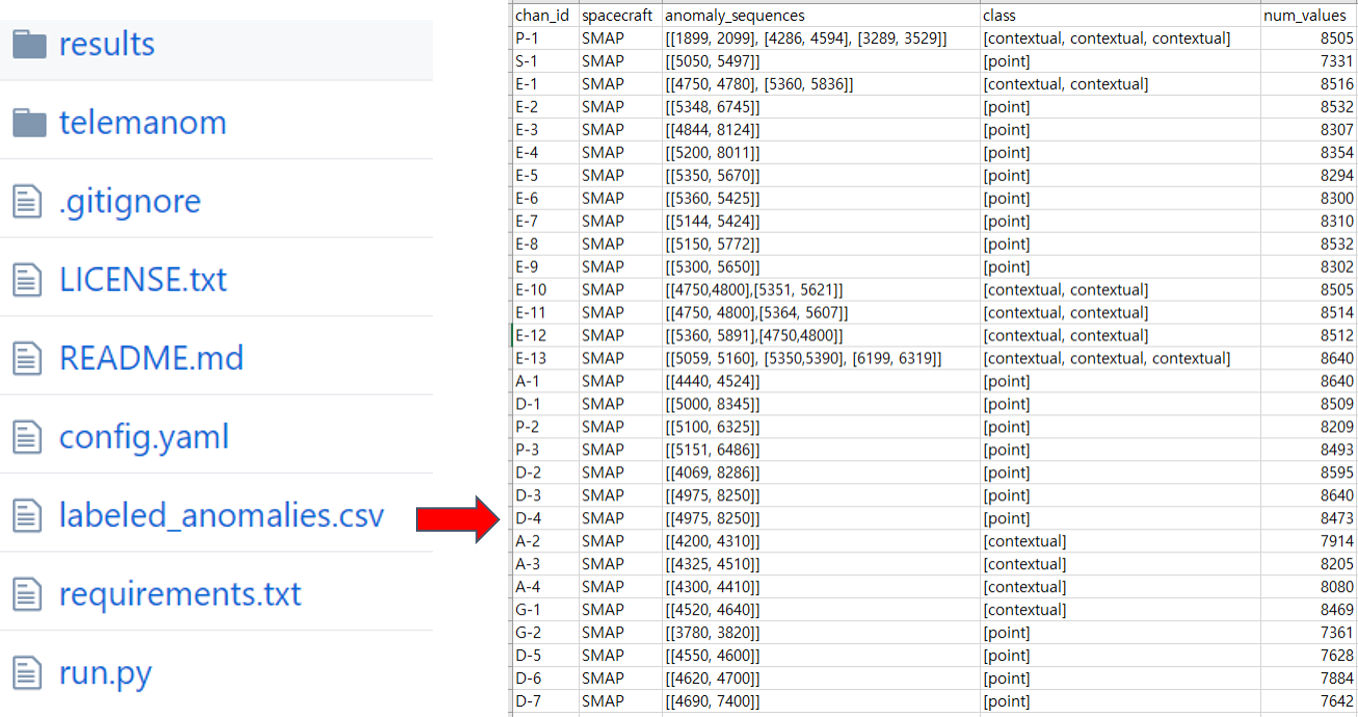
‘labeled_anomalies.csv’ 파일 상세설명 입니다. 이상의 종류(point, contextual)까지 라벨링 하였습니다.

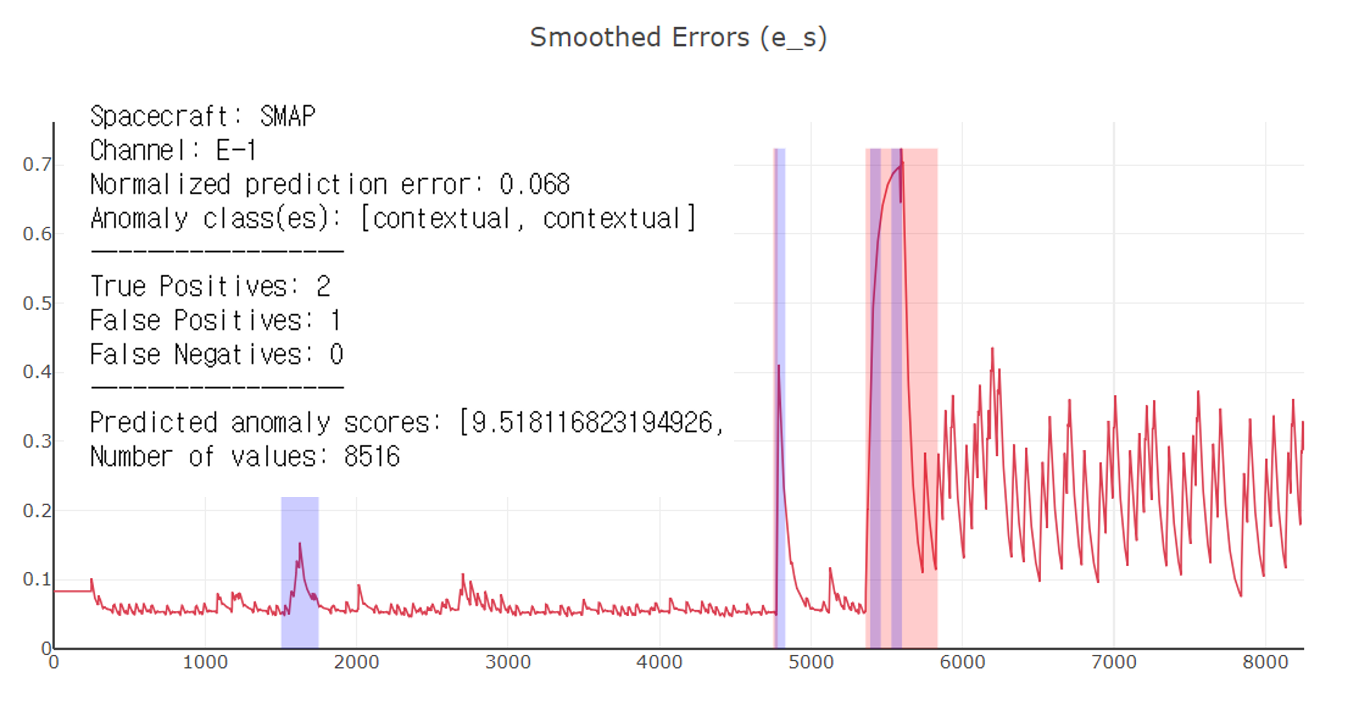
모델 결과 화면
아래는 테스트 데이터 셋을 이용한 모델 성능평가 담긴 사진입니다.