본 포스트에서는 Test Time Augmentation에 대해서 소개하고, 관련 코드도 리뷰하도록 하겠습니다.
Data Augmentation에 대해 자료조사를 하던 중, TTA(Test Time Augmentation)에 대해 알게되어, 관련 소개를 하고 간단하게 구동할 수 있는 코드도 리뷰하도록 하겠습니다.
모든 그림과, 소스코드 등은 아래의 게시글에서 모두 참조하였습니다.
https://www.kaggle.com/andrewkh/test-time-augmentation-tta-worth-it
https://towardsdatascience.com/test-time-augmentation-tta-and-how-to-perform-it-with-keras-4ac19b67fb4d
TTA란?
딥러닝 모델을 학습시킬 때, 데이터가 부족하는 등의 문제가 생기면 데이터 Augmentation을 사용합니다. 기존에 있는 데이터 셋을 회전/반전/뒤집기/늘이기/줄이기/노이즈 등 다양항 방법을 사용하여 부풀립니다.
Test Time Augmentation(TTA)도 augmentation하는 방법은 같습니다. 하지만 학습할 때 augmentation하는게 아닌, 테스트 셋으로 모델을 테스트하거나, 실제 운영할 때 augmentation을 수행하는 것 입니다.
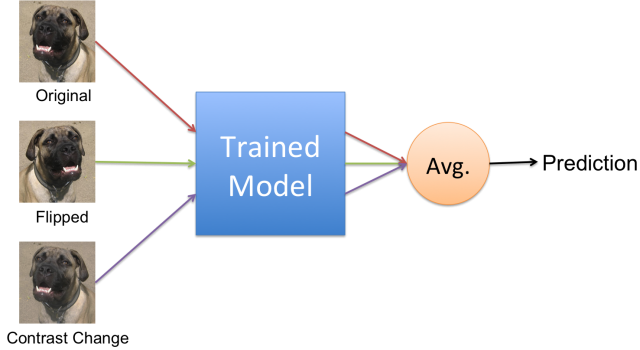
위 사진을 예로 들자면, 원본 입력 이미지 한장을 augmentation해서 2장 더 만들었습니다. 총 3장의 이미지를 학습된 모델에 각각 입력해주고, 모델에서 나온 결과는 모두 평균화하여 최종 결과를 도출하게 됩니다. TTA의 메인 아이디어는 원본 이미지 한장만 입력받아 결과를 예측하는 것이 아니라, 원본이미지를 augmentation한 다양한 관점의 이미지들을 입력받아 최종 결과를 도출하는 것 입니다.
좀 더 자세한 예를 들어보겠습니다.

학습된 분류 모델에 위 테스트 이미지를 입력하여 분류 결과를 에측하려고 합니다. 테스트 이미지를 모델에 입력하면 아래와 같이 각 클래스에 대한 예측 확률이 나옵니다. 가장 높은 확률을 최종 도출하므로 2번째 클래스로 예측을 합니다.
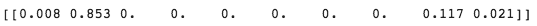
그리고 테스트 이미지의 정답은 아래와 같다고 할 때,
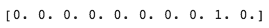
모델에 예측한 분류 결과는 틀렸다는 걸 알 수 있습니다. 모델은 2번째 클래스의 확률이 가장 높다고 예측하였지만, 정답은 9번째 클래스였습니다.
만약 위 상황에서 Test Time Augmentation을 적용한다면 어떻게 될까요? 같은 이미지를 약간만 변형시킨 5장의 이미지를 모델에 입력해보고, 분류 결과를 예측해 보겠습니다.

모델에서 출력된 각 이미지들의 클래스 확률은 다음과 같습니다.
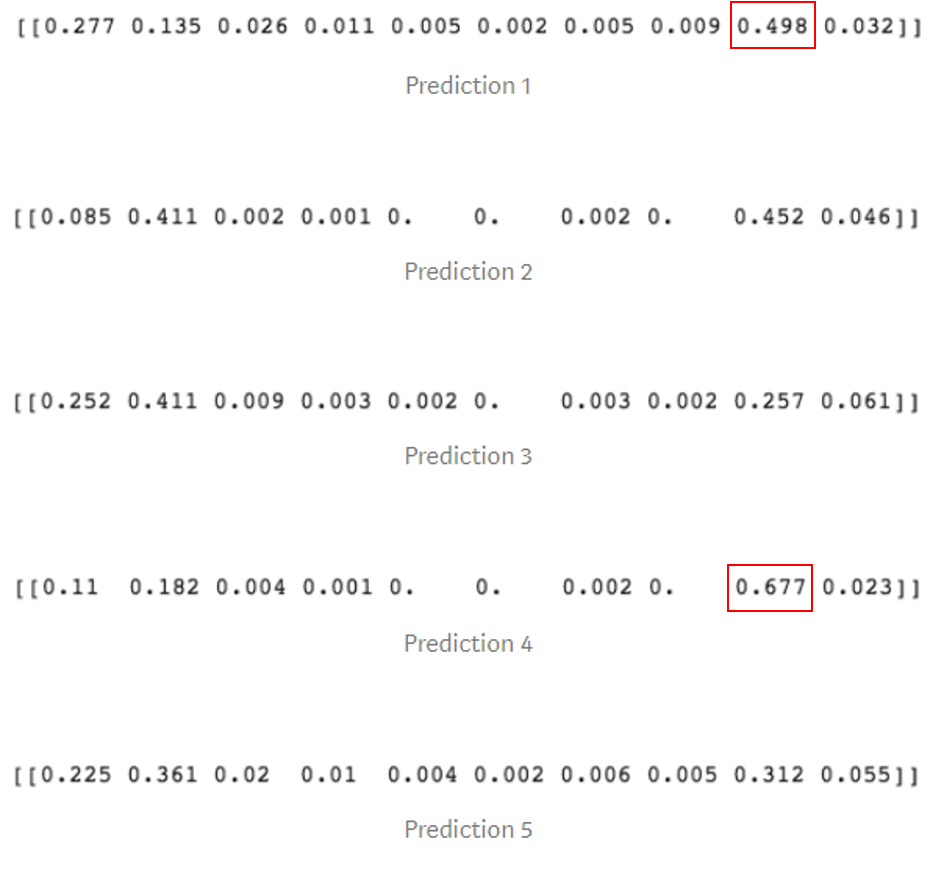
보시다시피, 1번과 4번 이미지는 9번째 클래스 분류 확률(결과)이 가장 높게 나왔습니다. 2번 이미지는 2번째와 9번째 클래스 분류 확률의 차이가 매우 적고, 3번과 5번 이미지는 분류 결과가 틀렸습니다. 이제 5장의 결과를 모두 평균화하면 어떻게 될까요?
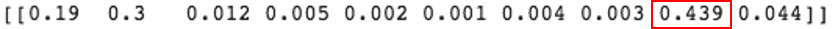
위 그림에서 보이는 것 처럼, 9번째 클래스의 예측 확률 값이 제일 높으므로 정답과 일치합니다. 원본이미지 1장만으로 분류했을 때는 결과가 틀렸지만, 5장의 이미지를 이용하여 분류하니 정답을 맞혔습니다.
이 방법이 작동하는 이유는 랜덤으로 수정한(augmentation한)이미지들의 예측과 오류를 평균화하기 때문입나다. 이미지 1장에서 에러는 큰 값으로, 오답이 나올 확률이 큽니다. 하지만 다양한 이미지에서 나온 n차원 이상의 에러를 평균화하면 오답을 비껴갈 수 있습니다.
TTA는 모델의 예측이 불확실한 테스트 이미지에 적용할 때 큰 효과를 볼 수 있습니다. 사람이 5장의 이미지를 봤을 떄는 굉장히 비슷하게 보였겠지만, 실제 모델은 전혀 다른 예측결과를 내놓았습니다.
케라스에서 TTA 사용하기
TTA는 케라스에서 쉽게 구현할 수 있습니다. 먼저 굉장히 간단한 CNN 네트워크를 만들고, CIFAR10 데이터를 학습시켜보겠습니다.
model = Sequential()
model.add(Conv2D(64,(3,3), activation='relu', input_shape=(32,32,3)))
model.add(Conv2D(128,(3,3), activation='relu'))
model.add(Conv2D(128,(3,3), activation='relu'))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
Keras의 ImageDataGenerator 클래스를 활용하여 학습 데이터 셋을 augmentation 할 수 있습니다.
train_datagen = ImageDataGenerator(
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rotation_range=10.,
fill_mode='reflect',
width_shift_range = 0.1,
height_shift_range = 0.1)
train_datagen.fit(x_train)
네트워크를 학습 시킵니다.
history = model.fit_generator(train_datagen.flow(x_train, y_train,
batch_size=bs),
epochs=15,
steps_per_epoch=len(x_train)/bs,
validation_data=(x_val, y_val))
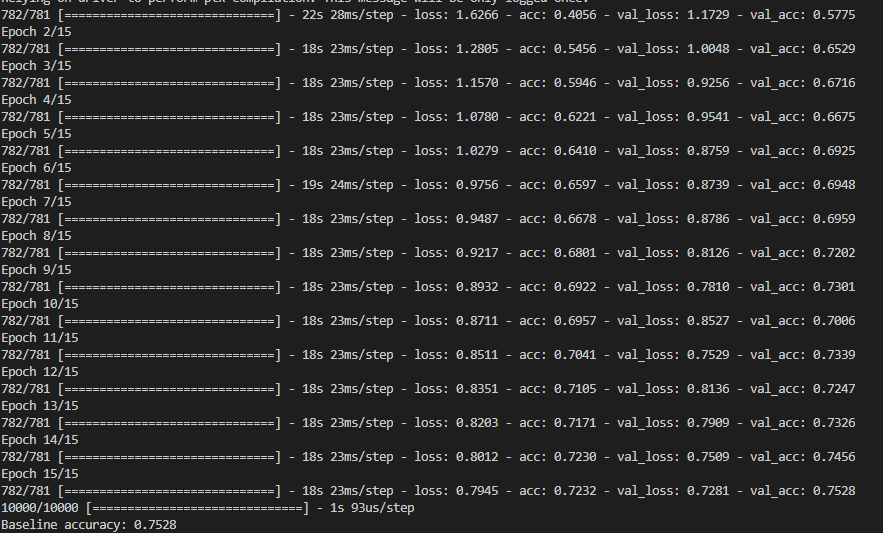
검증셋으로 평가한 모델의 최종 정확도는 다음과 같습니다.
모델 학습 데이터 셋에 사용했던 _DataGenerator_를 검증 셋에 사용해서 TTA를 적용합니다.
우리는 한 장의 원본 이비지를 10장의 랜덤으로 수정된 이미지를 사용하여 모델에 입력하여, 각각 예측을 하고, 평균화할 것 입니다.
tta_steps = 10
predictions = []
for i in tqdm(range(tta_steps)):
preds = model.predict_generator(test_datagen.flow(x_val, batch_size=bs, shuffle=False), steps = len(x_val)/bs)
predictions.append(preds)
final_pred = np.mean(predictions, axis=0)
print(f'Accuracy with TTA: {np.mean(np.equal(np.argmax(y_val, axis=-1), np.argmax(final_pred, axis=-1)))}')
TTA를 적용했을 때의 검증셋 정확도는 다음과 같습니다.

TTA를 적용하니 2~3%의 성능개션 효과가 있었습니다. 모델을 변경하지 않고, 2~3%의 정확도 향상은 의미있는 일 입니다.
More data augmentation isn’t always better
데이터 Augmentation은 효과적인 성능개선 기법이지만, 현명하게 사용해야 합니다. 올바르게 사용하지 않으면, 오히려 모델의 정확도가 떨어질 수 있습니다.

위 이미지에서 각 이미지에 표시된 숫자를 각각 말할 수 있나요?
한트를 주자면, 이미지에 6은 없습니다…
Augmentation하는 데이터의 종류는 데이터에 따라 다릅니다. MNIST의 경우, 너무 큰 회전 또는 뒤집기 등을 수행하면, 이미지의 원본 내용을 완전히 바꾸게 됩니다. 숫자 6 을 회전하거나 뒤집게 되면, 숫자 9 가 되는 것 처럼 말이죠. 모델에서는 이러한 차이를 학습하기 매우 힘들어집니다.
하지만 CIFAR10의 데이터셋 인 경우, 수평 뒤집기 등을 수행해도 이미지의 내용은 크게 바뀌지 않습니다. 말이 왼쪽을 보던, 오른쪽을 보던, 큰 변화가 없습니다. 그러나 수직뒤집기는 문제가 생길 수 있습니다. 거꾸로된 선박은 모델에서 제대로 인식하지 못할 확률이 높습니다.
위성 이미지, 농작물(벼, 논, 밭 등) 이미지에서는 뒤집기, 회전 등은 이미지의 내용을 바꾸지 않으므로, 사용할 수 있습니다.
결론적으로, 데이터 Augmentation을 올바르게 학습과 테스트에 사용한다면, 모델의 성능개선 효과를 가져올 수 있습니다.
링크에 전체 소스 코드가 있으니 참고하셔도 좋을 것 같습니다.