본 포스트에서는 딥러닝 LSTM-AutoEncoder 기반 이상감지 모델 대해 간략하게 설명하도록 하겠습니다.
작성자 : 박상민 - (주)인스페이스 미래기술실 연구원
본 포스트는 약 4개월간 이상감지(Anomaly Detection)를 연구하게 되면서 공부했던 것, 알아낸 것, 찾아봤던 자료, 구현체, 결과물 등을 정리해서 공유하는 글 입니다.
주관적인 내용이 포함되어 있으니 이해해주시기 바랍니다. 항공우주분야의 이상감지를 연구해왔기 때문에 글의 내용도 도메인에 밀접한 내용이 있으니 참고하시면 좋을 것 같습니다.
LSTM-AutoEncoder 이상감지 모델
RNN의 장점 중 하나는 이전의 정보를 현재의 문제 해결에 활용할 수 있다는 것 입니다. 비디오에서 바로 전의 프레임이 현재 프레임을 해석하는데 도움을 줄 수 있습니다. 하지만 RNN은 길이가 긴 시퀀스를 처리하기 어렵고, Vanishing Gradient 문제를 가지고 있습니다.
Vanishing Gradient Problem은 인공신경망이 기울기 값이 사라지는 현상입니다. 인공신경망은 기울기를 이용해 역전파로 학습합니다. Gradient 즉, 변화량이 굉장히 작다면 네트워크를 효과적으로 학습시키지 못할 것입니다. Gradient가 0에 수렴할수록, 네트워크의 학습속도는 굉장히 느려질 것이고, local minimum에 도착할 것 입니다.
이를 해결하기 위해 가중치를 잘 초기화 하는 방법, ReLU activation 함수를 사용하는 방법 등이 있습니다. 아래 그림 출처
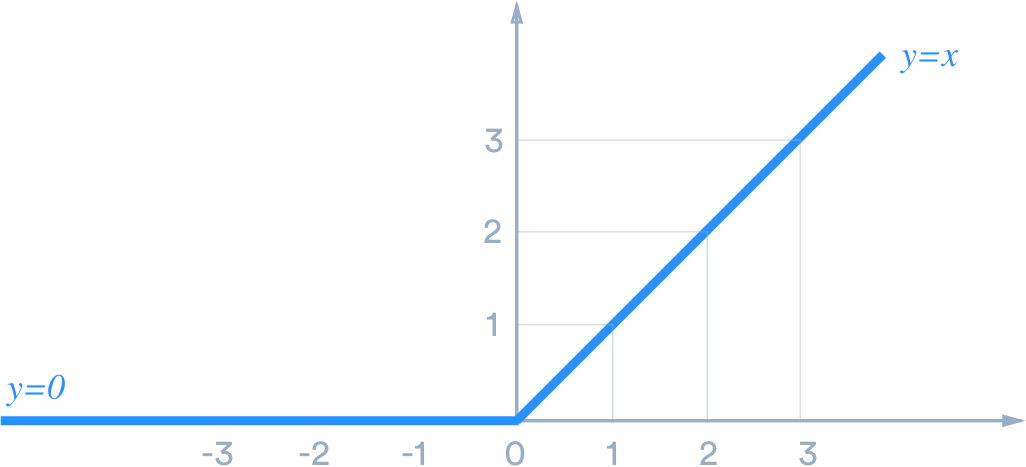
좀 더 확실한 해결책은 Long Short-Term Memory(LSTM)또는 Gated Recurrent Unit(GRU)구조를 사용하는 방법입니다. LSTM과 GRU모두 vanishing gradient 문제를 해결하기 위해 설계되었고, 킨 시퀀스를 처리할 수 있다는 것을 보여주었습니다.
오토인코더란?
지도학습 방식은 데이터의 입력값과 목표값(target)이 모두 주어진 라벨링된 데이터를 모델 학습에 사용합니다. 반대로 비지도학습 방식은 데이터의 입력값만 주어진 상태로 모델을 학습합니다.
AutoEncoder Neural Network(AutoEncoder, 오토인코더)는 비지도학습 방식입니다. 오토인코더의 목표값은 있지만, 입력값과 같습니다. 모델에 입력된 값과 똑같이 모델의 출력에도 나와야 합니다.
아래사진은 오토인코더의 가장 기본적인 구조입니다. 아래구조에서 오토인코더는 h(x)(가설함수)가 되는 함수를 학습하고자 합니다. 즉 출력값을 입력값 x와 유사하게 만들고자 하는 것 입니다. 아래 그림 출처
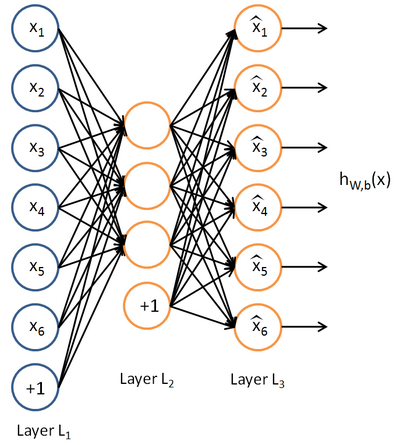
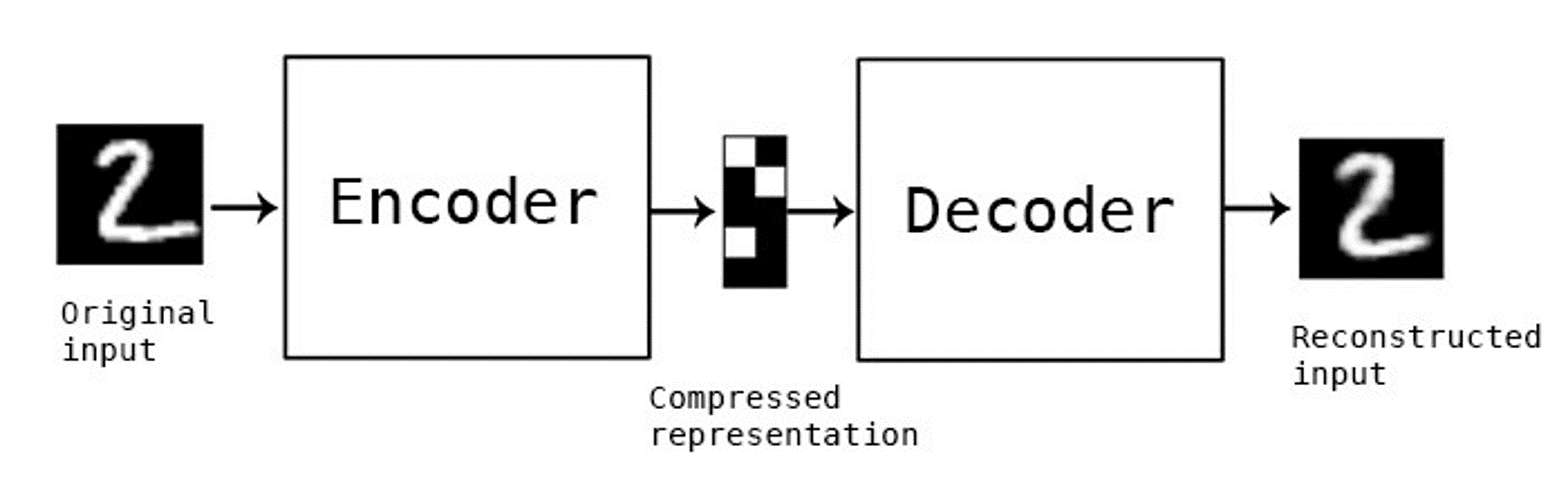
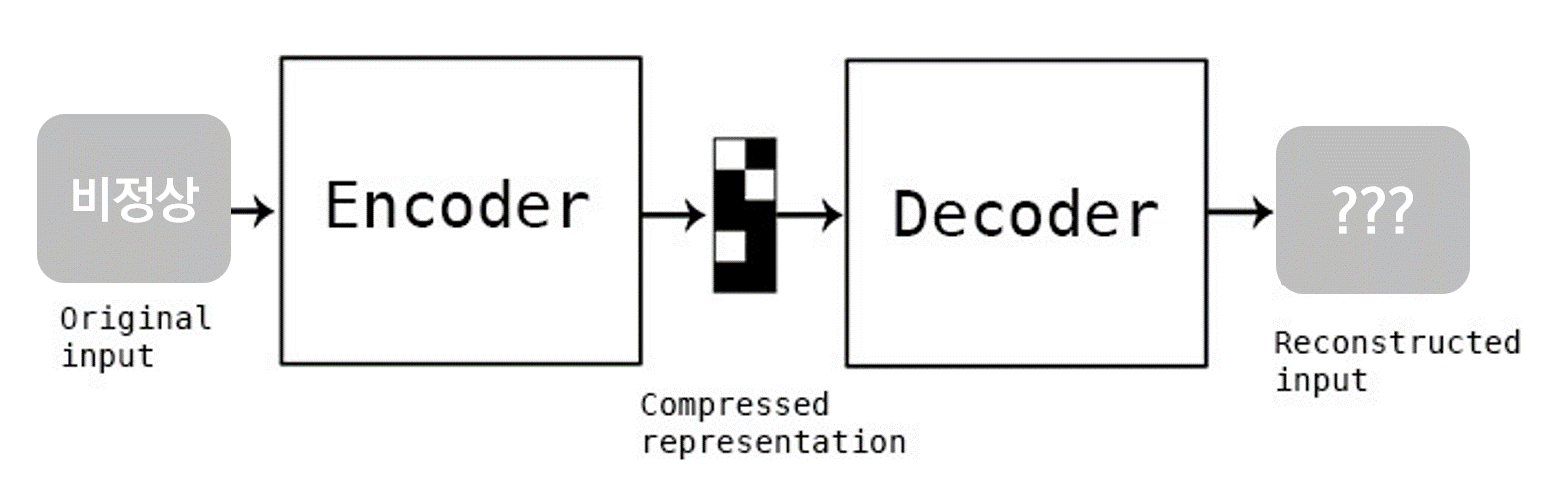
아래 사진과 같이 오토인코더 모델에 2를 넣게되면 인코더에 의해 압축됩니다. 압축된 표현은 디코더에 의해 다시 복원되어집니다.
오토인코더 모델은 히든레이어의 유닛 수가 모델 입력부분 유닛수에 비해 적습니다. 즉 인코딩 되면서 모델은 중요한 정보(특정 feature)만 살리게 됩니다.
압축된 표현을 디코더로부터 복원시킬 수도 있고, 다른 네트워크에 추출한 특징을 입력해 줄 수도 있습니다. 아래 그림 출처
오토인코더를 사용하는 이유
대부분의 도메인에서 이상(anomaly)데이터는 충분하지 않습니다. 우리는 이러한 문제를 데이터 불균형이라고 부릅니다. 총 10000개의 데이터 중 9999개가 정상이고, 남은 1개가 이상데이터인 경우도 있습니다. 얼마안되는 이상데이터들도 명확하게 분류하지 못하는 문제도 생깁니다.
정상데이터만 굉장히 많고, 이상데이터가 거의 없는 상황에서 오토인코더를 적용할 수 있습니다. 오토인코더는 입력과 타겟이 같도록 학습합니다.
정상데이터를 모델에 입력해주고, 똑같이 출력에 나오도록 학습시키면, 모델은 입력된 정상 데이터와 똑같은 데이터를 출력할 것 입니다. 아래 그림 출처
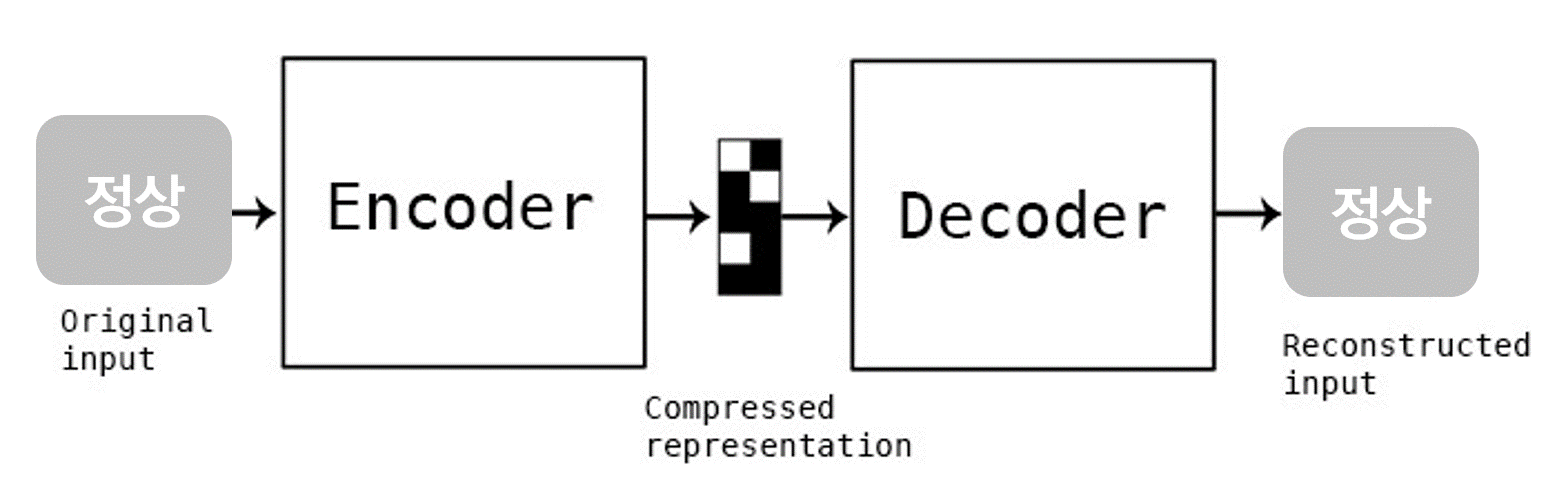
정상 데이터로만 학습시킨 오토인코더 모델은 정상데이터가 입력되면 똑같이 출력할 것입니다. 만약, 기존에 학습했던 정상 데이터가 아닌 비정상 데이터(정상 데이터와는 다른)가 모델에 입력되게 된다면 모델의 출력(복원)은 입력 값이랑은 차이가 많이 날 것입니다. 기존에 학습하지 않은 데이터이기 때문이죠.
이상감지에는 복원 에러(Reconstruct ion Error)를 사용합니다. (모델 입력 - 모델 출력) = Error 를 사용하여 임계치(Threshold)를 정하고, 에러가 임계치를 넘게 되면 이상이라고 정의하는 것 입니다. 아래 그림 출처
정상데이터만 굉장히 많은 경우에 오토인코더는 효율적으로 학습시켜 적용시킬 수 있습니다. 비정상 데이터가 거의 없거나, 존재하지 않는 상황에서도 적용시킬 수 있으며, 정상과 비정상만 명확하게 구분해놓으면 데이터를 라벨링할 필요가 없어지게 됩니다.
LSTM-AutoEncoder(LSTM-AE)
시계열 데이터의 이상감지는 시간적인 특성을 고려해야 합니다. 시간적인 특성을 담고싶다면, LSTM 네트워크를 이용해야 합니다. 기존의 오토인코더는 시간적 특성을 담을 수 없으므로, LSTM 레이어를 이용해 오토인코더를 구성해야 합니다. 뿐만 아니라 인코더와 디코더 레이어를 더 쌓아줘서 깊은 추론을 하게끔 할 수도 있습니다.
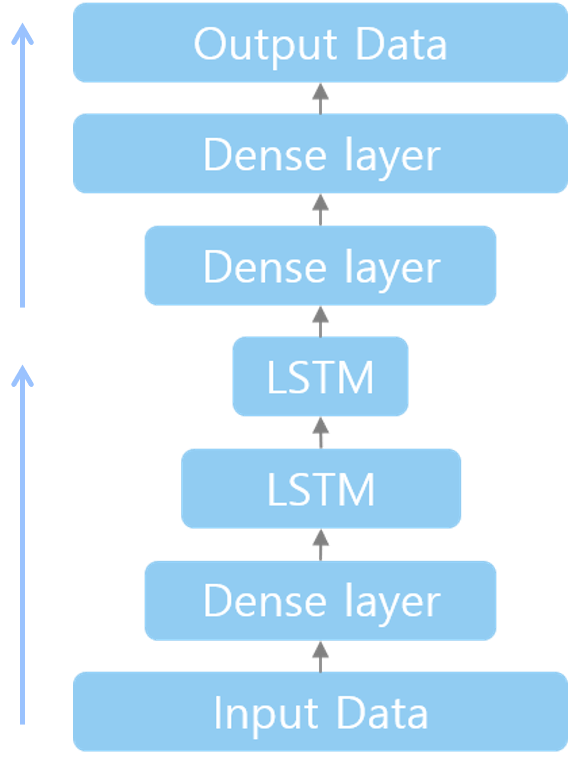
아래 사진은 제가 구성한 LSTM-AE의 구조입니다. Dense 레이어와 LSTM 레이어를 함께 사용하였고, 인코더와 디코더에 레이어를 추가하였습니다.
LSTM-AE를 이용한 데이터 복원
임의로 sin, tan함수를 이용해 데이터를 만들어 보았습니다. sin함수는 정상데이터이고, tan함수는 비정상 데이터라고 가정하고 진행하였습니다. 여러개의 sin함수를 이어 붙여서 정상데이터를 만들고, 오토인코더 모델에 학습시켰습니다.
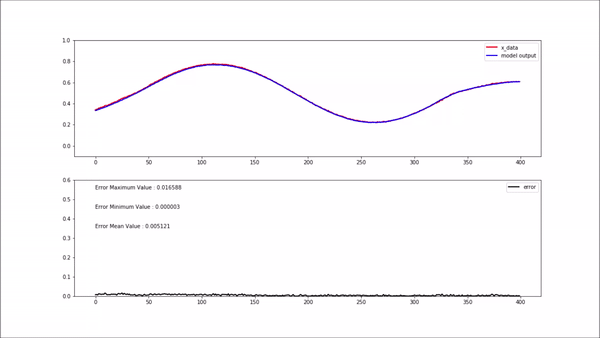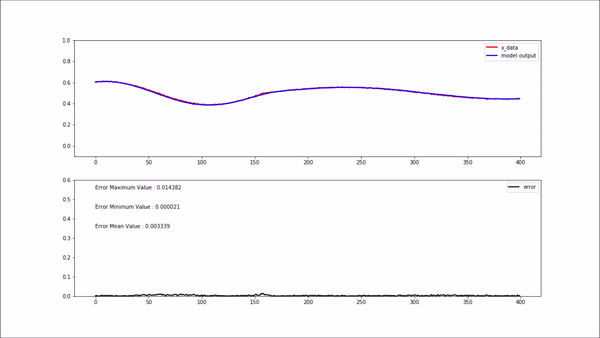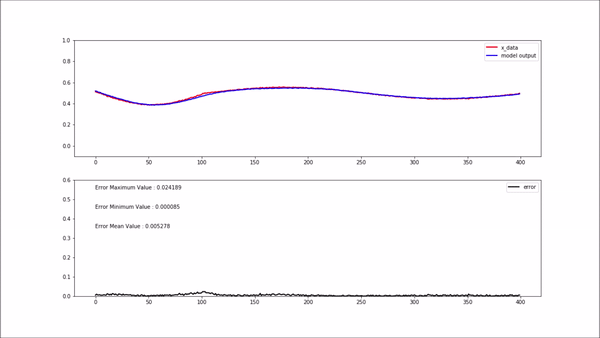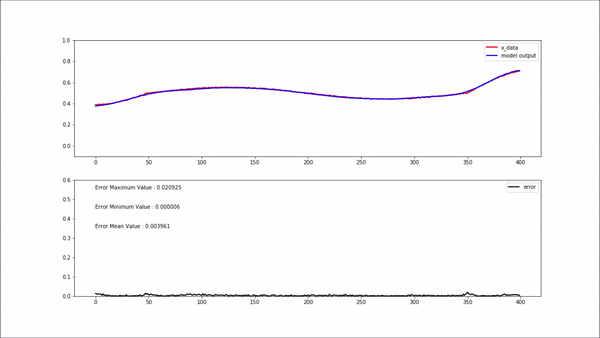
위 gif 상단에 있는 plot에서 빨간색 선은 모델 입력 값이고, 파란색 선은 모델 출력(복원) 값 입니다.
하단에 있는 plot의 검은색 선은 복원 에러 입니다. 정상인 데이터를 모델에 입력해 주었을 때는 에러가 굉장히 작게 나오는 걸 볼 수 있습니다.
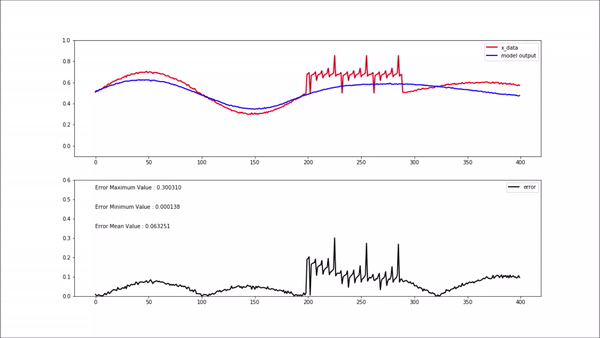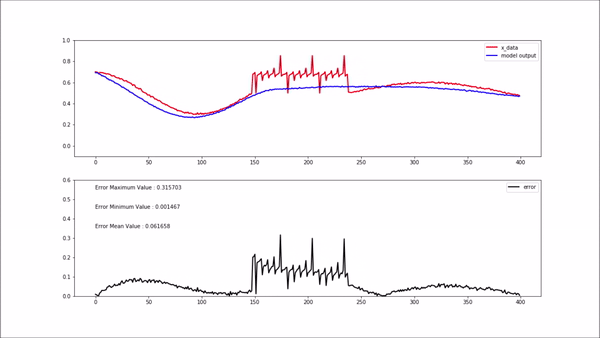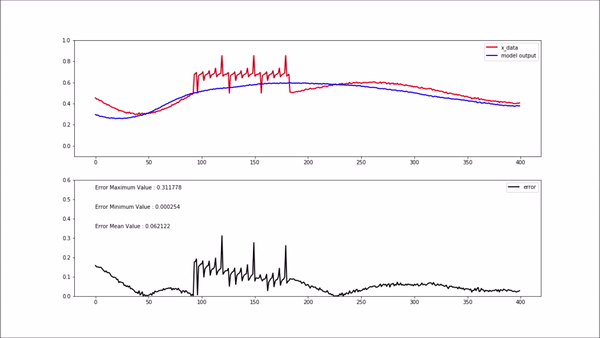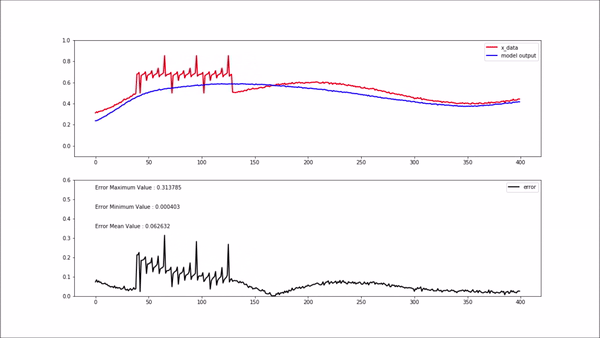
비정상 데이터(학습되지 않은 새로운 데이터)가 모델에 입력되면 위 gif와 같이 복원 에러가 굉장히 높게 나옵니다. 복원 에러가 높게 나와 임계치를 넘어선다면 비정상구간이라고 정의할 수 있습니다.
Dynamic Error Thresholds
AE 모델의 Error는 reconstruction error(복원 에러)로써 모델의 출력 값 - 모델 입력 값 입니다. 에러를 계산하는 이유는 AE모델은 정상 데이터만으로 학습하였기 때문에, 정상 데이터가 입력되면 출력도 매우 유사하게 출력됩니다(차이가 적습니다). 하지만 비정상데이터(지금까지 보지 못한 데이터)가 입력으로 들어오면, 모델은 입력과는 매우 다른 출력을 할 것입니다(차이가 클 것입니다). 복원에러를 이용하면 비정상데이터를 확보하지 못헀다하더라도, 정상과는 다른 데이터를 알 수 있을 것 입니다,
산출한 에러를 그대로 사용하는 것은 무리가 있습니다. 에러를 전처리 하지않고 그대로 사용하면, 정상적인 경우에서 에러값이 급격하게 증가하는 경우가 있습니다. 이를 보완하기 위해서는 에러 smoothing 후 사용해야 합니다. Error smoothing은 exponentially-weighted average(EWMA, 다변량 지수가중이동평균)을 사용해 smoothing 작업을 하게 됩니다.
EWMA는 데이터의 평균을 계산하는 알고리즘 중 하나인데, 오래된 데이터는 낮은 가중치를 주고, 최근 데이터는 포은 가중치를 부여하는 방법입니다. 이러한 방법은 평균을 계산하는데 최근 데이터가 더 많은 영향력을 행사하는 것으로, 최근 데이터에 더 민감하게 반응할 수 있게 해줍니다. 에러 Smoothing을 해줌으로써 에러 값의 포인트 하나가 급격히 증가하는 상황도 방지해 줄 것입니다.
에러를 전처리한 후 threshold를 지정해야합니다. Threshold는 도메인 전문가나, 개발자가 정상 데이터일 때 에러 값을 보고 임의로 지정할 수 도 있습니다. NASA에서 작성한 한 논문은 Dynamic Error Thresholds에 대해서 소개해줍니다. 에러 셋을 통해 threshold를 산출하고, 적용시키는 것 입니다. 각 에러 셋에 따라 Threshold가 달라질 수 있습니다. 이 방법은 에러 셋을 기반으로 threshold를 산출하기 때문에 편리하고 정확합니다.
위에서 설명드린 Error Setting, Smoothing, Dynamic Error Thresholds에 관해서는 논문에서 참고를 하였습니다. 논문에서 제안한 부분을 구현한 코드가 있어서 관련 코드도 공유해드립니다. 코드 error와 threshold에 관한 부분은 _errors.py_에 구현되어 있습니다.