본 포스트에서는 Active Learning의 목적은 무엇인지 어떤 방법으로 학습을 진행하는지에 대해서 알아보겠습니다.
Active Learning 개요
Active Learning은 주로 데이터 셋의 양이 너무 방대하여 라벨링 작업이 어려워 라벨링 작업에서 발생하는 병목현상을 해결하기 위해 사용됩니다.
모델(Learner)이 라벨링 되어있지 않은 데이터 중 학습에 보다 효율적인 데이터를 골라 전문가(Oracle)에게 요청(Query)을 날리고 전문가는 그 요청에 따라 데이터를 라벨링하면 모델은 라벨링 된 데이터를 받아 학습을 진행하는 형식입니다.
이와 반대로 제공받는 라벨링 데이터만을 가지고 모델을 학습시키는 방법을 Passive Learning이라고 표현합니다.
예제로 다음 그림을 살펴보겠습니다.
다음 그림의 왼쪽 부분은 좌표평면 상에서 0을 기준으로 하여 양 옆에 노이즈가 뿌려져 있는 것을 확인할 수 있습니다. 만약 이 데이터에 초록색과 빨간색 라벨링이 안되어있다고 가정을 해봅시다. 그러면 모든 점들을 라벨링하는 작업은 꽤나 어려운 작업이 될 것입니다. 그렇다면 유니폼하게 몇 개의 인스턴스를 뽑아 그 인스턴스들만을 라벨링을 진행하여 학습을 합니다. 그 학습을 한 회귀선을 표시한게 중간 그림입니다. 이는 보다 초록색 쪽으로 휘어있는 것을 확인할 수 있습니다. 즉, 빨간색으로 오검출되는 녹색 데이터가 많을 것을 의미합니다. 이 회귀선을 다시 학습하기 위해 다시 인스턴스들을 뽑을 때 보다 경계선에 가까운 인스턴스들(학습에 효율적인 인스턴스들)만을 라벨링하여 학습을 진행한 회귀선을 표시한 것이 오른쪽 그림입니다. 중간 그림에 비해서 오검출 데이터 비율이 낮아진 것을 확인할 수 있습니다. 이렇게 보다 효율적인 데이터 만을 라벨링하여 학습을 진행하면 보다 적은 라벨링 작업으로 좋은 모델을 얻을 수 있습니다.
Active Learning 시나리오
액티브 러닝에는 크게 3가지 종류의 시나리오가 존재합니다. 지금부터 모델이 전문가에게 라벨링 요청을 날리는 시나리오들에 대해서 살펴보겠습니다.
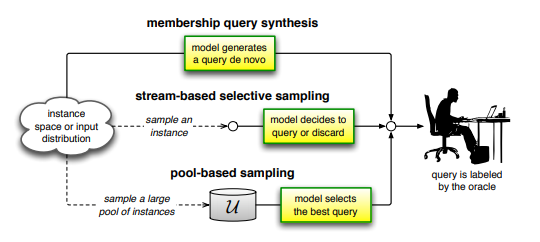
Membership Query Synthesis
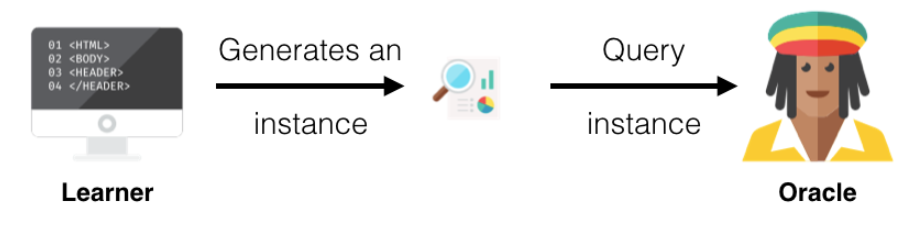
Membership Query Synthesis 시나리오는 모델이 어떤 분포에 의거하여 인스턴스를 생성하고, 이 인스턴스의 라벨링 작업을 전문가에게 요청하는 식입니다. 예를 들어 손글씨 한자리 숫자 데이터를 분류하는 모델을 학습한다고 했을 때, 모델이 손글씨 숫자 이미지를 생성하여 전문가에게 라벨링 요청을 하는 것입니다.
Stream-Based Selective Sampling
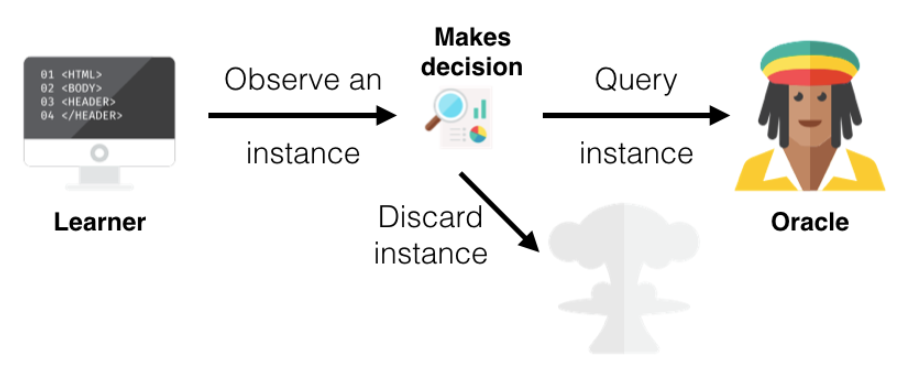
Stream-Based Selective Sampling 시나리오는 레이블이 없는 인스턴스들 중 하나를 뽑아 설정 기준에 따라 전문가에게 라벨링 요청을 날릴 것인지 아니면 버릴 것인지를 결정하는 것입니다. 라벨링 요청을 날린다면 라벨링된 인스턴스를 가지고 학습을 하는 것이고 그렇지 않다면 인스턴스를 버리고 다음 인스턴스를 찾아 또 기준에 따라 라벨링 작업 유무를 판단하게 됩니다.
Pool-Based Sampling
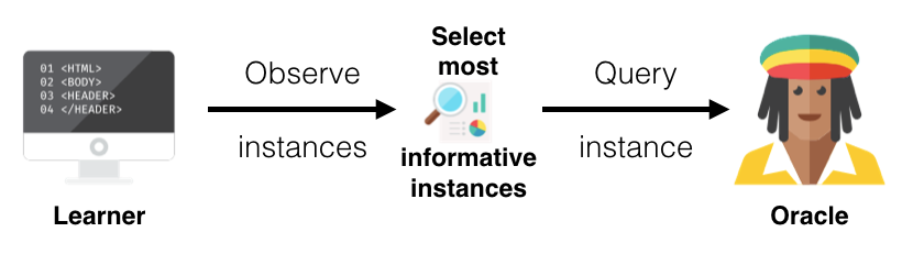
Pool-Based Sampling 시나리오는 Stream-Based Selective Sampling과 비슷하게 레이블이 없는 인스턴스들이 존재하고 인스턴스 별로 학습의 효율성을 나타내는 지표를 측정하여 가장 학습에 더 효율적이라고 생각하는 데이터를 뽑아 전문가에게 라벨링 요청을 하는 것입니다.
Query Strategies
모델이 전문가에게 라벨링 요청을 날릴 인스턴스를 뽑는 전략들에 대해 살펴보겠습니다.
다음 두 개의 인스턴스를 예를 들어 설명하겠습니다.

Least Confidence (LC)
Least Confidence 전략은 인스턴스를 보고 모델이 예측한 클래스의 확률 중 제일 큰 값이 가장 작은 인스턴스를 선택하는 전략입니다. 위의 예시에서 인스턴스별 가장 높은 확률은 d1: 0.9, d2:0.5로 d2가 더 작은 것을 알 수 있습니다. 따라서 이 전략에 따르면 d2를 전문가에게 라벨링 작업을 요청합니다.
Margin Sampling
Margin Sampling 전략이 Least Confidence 전략과 다른 점은 클래스 확률 중 제일 큰 값과 두번째 값의 차이 중 제일 작은 인스턴스를 택하는 것입니다. 위의 예시에서 직접 계산을 해보면 d1: 0.81 (0.9-0.09) , d2: 0.2 (0.5-0.3)으로 d2가 더 작은 것을 알 수 있습니다. 따라서 이 전략에 따르면 d2를 전문가에게 라벨링 작업을 요청합니다.
Entropy Sampling
Entropy Sampling 전략은 모델이 예측한 클래스 확률 정보를 모두 사용하여 측정할 수 있는 엔트로피를 이용합니다. 즉 엔트로피가 가장 높은 인스턴스를 선택해 저문가에게 라벨링 작업을 요청합니다. 위의 예시에서 인스턴스별 엔트로피 계산을 하면 d1: 0.155, d2: 0.447로 d2의 엔트로피가 더 높은 것을 알 수 있습니다. 따라서 이 전략에 따르면 d2를 전문가에게 라벨링 작업을 요청합니다. 이 예시에서 사용한 엔트로피 식은 다음과 같습니다.
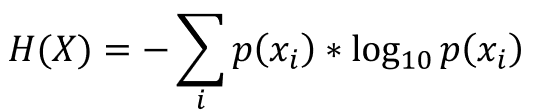
위 식에서 X는 확률변수이고, x는 각 사건들을 의미합니다. 위 예시에서는 밑이 10인 로그를 사용하여 계산했습니다.
Reference
- https://www.datacamp.com/community/tutorials/active-learning
- http://burrsettles.com/pub/settles.activelearning.pdf