본 포스트에서는 gym 환경 중 하나인 CartPole-v1 환경에서 강화학습 알고리즘들을 구현하고 비록 간단한 환경이지만 알고리즘들의 성능 비교 내용을 다뤄보겠습니다. 저장소 링크는 아래와 같습니다.
- https://github.com/InSpaceAI/RL-Zoo
CartPole-v1 환경 설명
CartPole-v1 은 OpenAI의 gym 라이브러리를 통해 플레이할 수 있는 간단한 환경 중 하나입니다. CartPole은 말 그대로 카트를 조종하여 막대기를 제어하는 게임입니다. CartPole-v1 에서는 아래 그림과 같이 카트 위에 막대기가 있고, 막대기의 끝부분(하단)은 카트에 연결되어 있습니다.
상태(State) 설명
매 스텝마다 관측할 수 있는 환경의 정보는 4개로 구성되어 있고 요소는 다음과 같습니다.
- 카트의 위치
- 카트의 속력
- 막대기의 각도
- 막대기의 끝부분(상단) 속도
행동(Action) 설명
매 스텝마다 0, 1의 값을 통해 카트를 좌, 우로 조종할 수 있습니다.
보상(Reward) 설명
매 스텝마다 카트가 중심을 기준으로 일정 범위 안에 있고, 막대기가 넘어지지 않으면 +1의 보상을 받습니다. 즉 막대기의 중심을 잘 잡아 넘어 뜨리지 않고 오래 버티면 성공하는 게임입니다.
구현한 강화학습 알고리즘
구현한 강화학습 알고리즘은 DQN, REINFORCE, A2C, DDPG, PPO(DDPG와 PPO는 Continuous Action으로 구현하였고, DDPG(sigmoid)는 액션이 0.5보다 작으면 0 크면 1로 설정, PPO(linear)는 액션이 0보다 작으면 0 크면 1로 설정)이고, 해당 알고리즘에 대한 논문링크는 다음과 같습니다.
- DQN 논문 링크 : https://arxiv.org/pdf/1312.5602
- REINFORCE 논문 링크 : http://papers.nips.cc/paper/1713-policy-gradient-methods-for-reinforcement-learning-with-function-approximation.pdf
- A2C 논문 링크 : https://arxiv.org/pdf/1602.01783
- DDPG 논문 링크 : https://arxiv.org/pdf/1509.02971
- PPO 논문 링크 : https://arxiv.org/pdf/1707.06347
알고리즘 하이퍼 파라미터 세팅
알고리즘 별 공통 하이퍼 파라미터는 최대한 동일하게 유지하였고 세팅은 다음과 같습니다
- 레이어 수 : 2 ,(DQN : 3)
- 히든 레이어 유닛 수 : 256, (DQN : 64)
- 활성화 함수 : ReLU
- 학습률 5e-3 (actor, critic 분리 모델은 각각 1e-3, 5e-3으로 설정, DQN : 2e-4)
- 감가율 : 0.99
- 시드(numpy, tensorflow, env) : 1
보상 그래프
총 1000 episode동안 학습을 진행하였고 이에 대한 보상 그래프는 다음과 같습니다.
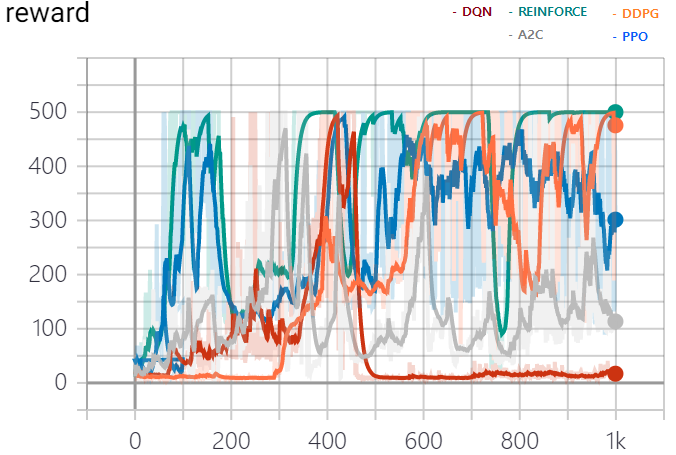
학습 중 500점을 받은 에피소드 횟수는 다음과 같습니다.
- DQN : 47
- REINFORCE : 629
- A2C : 60
- DDPG : 264
- PPO : 329
500점에 도달하여도 성능이 급격하게 떨어지는 양상을 많이 볼 수 있습니다.
학습 중 최초로 마지막 10 에피소드의 평균 점수가 490이상에 도달하는 스텝은 다음과 같습니다.
- DQN : 428
- REINFORCE : 116
- A2C : 313
- DDPG : 648
- PPO : 103
도달 시 종료 그래프
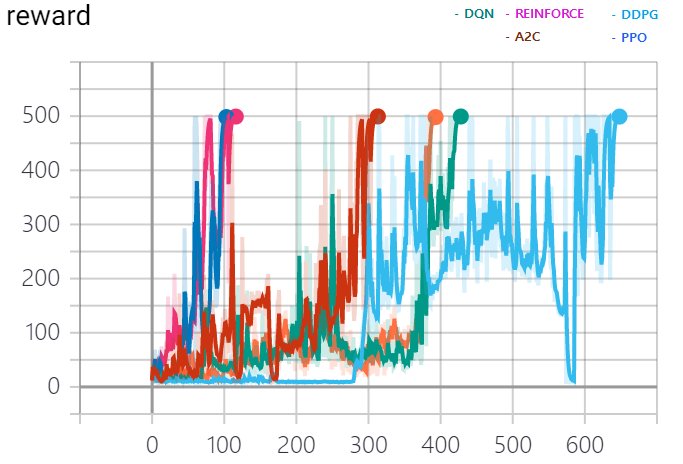
결론
강화학습 알고리즘 구현 및 성능 비교를 진행하면서 느낀점들에 대해 얘기해보도록 하겠습니다.
-
생각보다 사소한 하이퍼 파라미터에 따라 많은 성능 차이를 보였고, 많은 실험이 필요하다는 것을 알게 되었습니다.
-
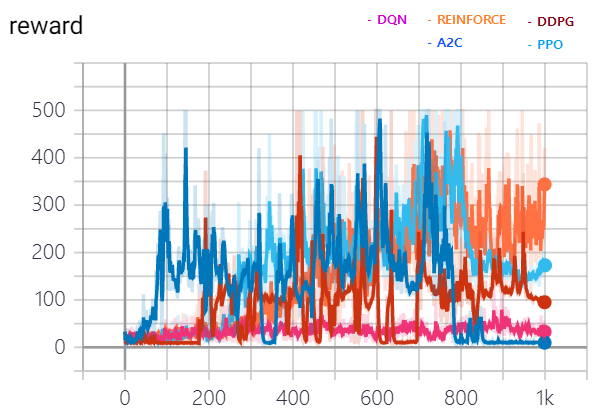
위의 세팅과 다르게 레이어 수를 3개로 히든레이어 유닛 수를 32로 하여 돌린 알고리즘들의 보상 그래프는 다음과 같습니다.
-
-
환경 시드에 따라서도 성능 차이가 생길 수 있다는 것을 알게 되었습니다. 아래의 그림은 환경 시드만 고정하지 않고 학습을 진행한 A2C의 보상 그래프 입니다.
-
-
강화학습 알고리즘도 중요하지만, 좋은 하이퍼 파라미터 찾는 과정도 중요하다고 느꼈습니다.
참고자료
아래 사이트들의 도움을 받아 코드 구현을 진행하였습니다.
- https://github.com/rlcode/reinforcement-learning-kr
- https://github.com/reinforcement-learning-kr/Unity_ML_Agents
- https://github.com/RLOpensource/tensorflow_RL
- https://github.com/RLOpensource/spinning_up_kr
- https://github.com/seungeunrho/minimalRL