본 포스트에서는 AutoML 라이브러리 중 하나인 H2O 설치와 예제 소스코드에 대한 설명이 들어있습니다.
H2O AutoML 시작하기
본 문서는 H2O 구동환경 설치 및 기본적인 소스코드에 대한 예제가 들어있습니다.
목차는 다음과 같습니다.
- Python기반 H2O 구동환경 설치하기
- Python기반 H2O AutoML 소스코드 빌드하기
- H2O 불러오기
- 데이터 불러오기
- 데이터 전처리하기
- AutoML 빌드하기
언어는 Python을 사용하였습니다.
Python기반 H2O 구동환경 설치하기
기본적인 설치 방법은 링크를 참조하였습니다.
-
H2O를 설치한 PC 환경은 다음과 같습니다.
- OS : Windows 10
- CPU : Intel Core i7
- GPU : GTX 1050
- Anaconda : 4.6.14(conda 가상환경 사용)
- python3 : 3.6.8
- JAVA : JDK SE 1.8.0
- Use pip
-
Anaconda와 가상환경을 모두 설치한 후 JDK를 링크에서 설치합니다.
-
JAVA를 설치한 후 아래 절차에 따라 라이브러리를 설치해줍니다.
pip install requests
pip install tabulate
pip install “colorama>=0.3.8”
pip install futurepip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o
-
h2o가 잘 설치되었는지 확인하는 방법은 다음과 같습니다.
python
import h2o
h2o.init()
h2o.demo(“glm”)문제없이 코드가 실행된다면 h2o가 정상적으로 설치된 것 입니다.
-
만약 h2o를 제거하고 싶으시다면 아래의 명령어를 통해 제거할 수 있습니다.
pip uninstall h2o
Python기반 H2O AutoML 소스코드 빌드하기
본 소스코드는 Intro To H2O 와 AutoML Demo 두 예제를 참고하였습니다.
H2O 불러오기
h2o 파이썬 모듈을 불러오고, local h2o cluster를 초기화 시킵니다.
# H2O 라이브러리를 불러오고, local에서 H2O 클러스터를 실행시킵니다.
import h2o
# [nthreads]는 클러스터에서 몇개의 쓰레드를 할당해줄건지 지정해줄 수 있습니다.
# [max_mem_size]는 클러스터에 할당되는 메모리양을 지정해줄 수 있습니다.
# [nthreads=-1] -> 모든 쓰레드를 사용합니다.
# [max_mem_size=8] 또는 [max_mem_size='8G'] -> 최대 8GB의 메모리를 할당해줍니다.
# [max_mem_size='800M'] -> 최대 800MB의 메모리를 할당해줍니다.
h2o.init(nthreads=-1, max_mem_size=8)
h2o.init()을 호출시키면, h2o 클러스터가 초기화 되면서 h2o 클러스터
데이터 불러오기
다음으로 “bad loan(불량 대출)” 데이터 세트를 불러올 것 입니다. 본 문제는 대출이 불량인지 아닌지(ex. 대출 업체에게 상환하지 않음)를 예측하는 문제입니다(이진분류). 열 ‘bad_loan’은 대출이 불량이면 1이고 그렇지 않으면 0입니다.
loan_csv = "https://raw.githubusercontent.com/h2oai/app-consumer-loan/master/data/loan.csv"
# loan_csv = "../data/loan.csv"
# 데이터 셋을 불러옵니다.
# [h2o.import_file]을 사용하여 URL에 있는 데이터 셋도 불러올 수 있습니다.
data = h2o.import_file(loan_csv) # 163,987 rows x 15 columns
print(data.shape)

데이터 전처리하기
h2o를 사용하여 데이터를 보다 쉽게 전처리 할 수 있습니다.
#factor 형태로 인코딩
data['bad_loan'] = data['bad_loan'].asfactor()
print(data['bad_loan'].levels())
# 데이터 셋 학습(75%)/검증(15%)/테스트(15%)로 분할
splits = data.split_frame(ratios=[0.7, 0.15], seed=1)
train = splits[0] # 학습 데이터 셋
valid = splits[1] # 검증 데이터 셋
test = splits[2] # 테스트 데이터 셋
# 각 데이터 셋 행 출력
print(train.nrow)
print(valid.nrow)
print(test.nrow)
y = 'bad_loan'
x = list(data.columns)
x.remove(y) # 'bad_loan'열 제거
x.remove('int_rate') # 필요없는 열 제거
print(x)
AutoML 빌드하기
from h2o.automl import H2OAutoML
# H2O AutoML 인터페이스
# [max_runtime_secs] AutoML 빌드될 최대 시간 지정
# [max_models] AutoML이 빌드할 최대 모델 개수 지정
aml = H2OAutoML(max_models=10, max_runtime_secs=1000, seed=1)
# [x] predict column
# [y] response column
# [training_frame] 학습 데이터 셋
# [validation_frame] 검증 데이터 셋
aml.train(x=x, y=y, training_frame=train, validation_frame=valid)
# 빌드된 AutoML 모델 보여주기
lb = aml.leaderboard
print(lb.head(rows=lb.nrows))
# 빌드된 AutoML 모델 MOJO 포맷으로 저장
aml.leader.download_mojo(path="./")
# 빌드된 AutoML 모델 binary 파일로 저장
model_path = h2o.save_model(aml.leader, path="./product_backorders_model_bin")
# binary 포맷으로 저장한 모델 불러오기
saved_model = h2o.load_model(model_path)
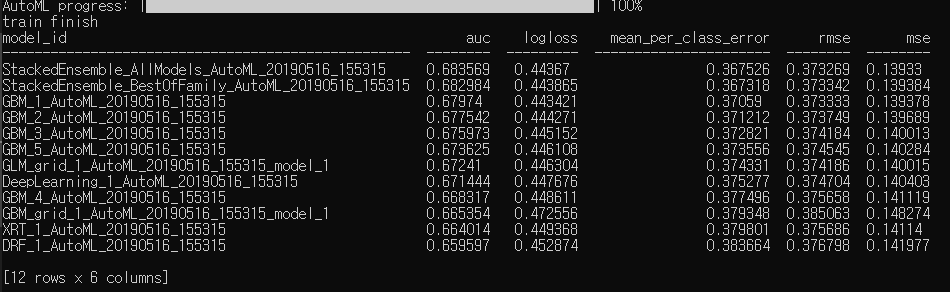
# AutoML 빌드 결과
train finish
model_id auc logloss mean_per_class_error rmse mse
-------------------------------------------------- ------ -------- -------------------- ------ -----
StackedEnsemble_AllModels_AutoML_20190516_155315 0.683569 0.44367 0.367526 0.373269 0.13933
StackedEnsemble_BestOfFamily_AutoML_20190516_155315 0.682984 0.443865 0.367318 0.373342 0.139384
GBM_1_AutoML_20190516_155315 0.67974 0.443421 0.37059 0.373333 0.139378
GBM_2_AutoML_20190516_155315 0.677542 0.444271 0.371212 0.373749 0.139689
GBM_3_AutoML_20190516_155315 0.675973 0.445152 0.372821 0.374184 0.140013
GBM_5_AutoML_20190516_155315 0.673625 0.446108 0.373556 0.374545 0.140284
GLM_grid_1_AutoML_20190516_155315_model_1 0.67241 0.446304 0.374331 0.374186 0.140015
DeepLearning_1_AutoML_20190516_155315 0.671444 0.447676 0.375277 0.374704 0.140403
GBM_4_AutoML_20190516_155315 0.668317 0.448611 0.377496 0.375658 0.141119
GBM_grid_1_AutoML_20190516_155315_model_1 0.665354 0.472556 0.379348 0.385063 0.148274
XRT_1_AutoML_20190516_155315 0.664014 0.449368 0.379801 0.375686 0.14114
DRF_1_AutoML_20190516_155315 0.659597 0.452874 0.383664 0.376798 0.141977